In this article
Fixing hallucination issues with LLMs
Learn how we at FunnelStory tacked LLM hallucinations with system prompts, function calling and chain of thought process. Learn strategies to fix hallucination issues with LLMs, making AI more reliable for enterprise use.

By Pulkit Banta
Frontend Developer
Jul 24, 2024
8 min read
Last Updated: Oct 28, 2025
In this blog post, I will focus on how we at FunnelStory overcame the challenges of LLM hallucination and the need for proper debugging while working with LLM.
Let’s start with an example of asking the ChatGPT to list 5 countries that start and end with the same letter along with having it to justify the response.

None of the countries that it responded with is correct and on top of that it even provides the justification for it. You can try to reproduce this issue on GPT-3.5.
There should always be a guardrail while developing on top of the LLM model as it is not always correct and is also limited by the training data. Let’s dive into the details now.
The issue
While developing the chatbot for FunnelStory, we encountered issues where the bot provided answers with data that didn't exist in our system. Since FunnelStory and our customers rely on accurate data, this poses a critical problem - either the data could be incorrect or the bot could be hallucinating, which is unacceptable.
Example
User: What are my most active accounts?
Felix:
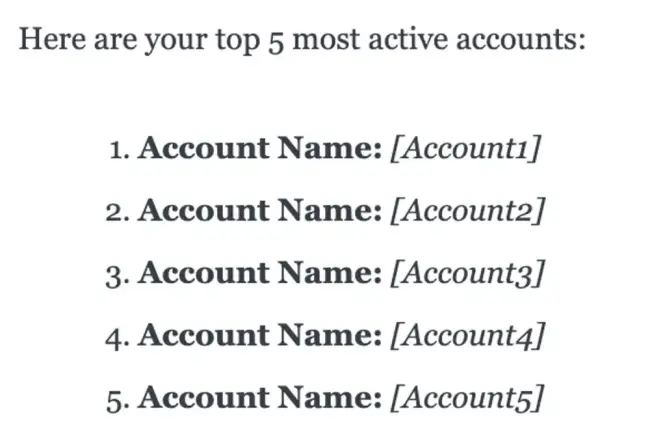
As seen in the example above, the response has accounts like `Account 1, Account 2...` but this is not the actual data present in our system. We pass functions to the LLM API call that it can call to get the data relevant to the user query but in this case none of the provided functions were called in order to get this data and instead the bot hallucinated and gave out the result. Upon repeating the question, the bot then provided the expected answer, listing the most active accounts based on generated activities and signals. Hence the main problem that we had is that the bot was not calling the correct functions or not calling the functions at all to get the data.
Reduce LLM hallucination while maintaining the accuracy
In this section, we'll discuss the various changes made to improve hallucinations and enhance our chatbot's accuracy in aligning with the system's data.
System Prompts
System prompts are messages passed to the chatbot with the 'system' role. They outline what the bot can and cannot do, specify response formatting, and provide additional platform context.
At FunnelStory, these prompts include details on permissible bot responses to prevent internal information leaks, enforced with code checks as a safeguard.
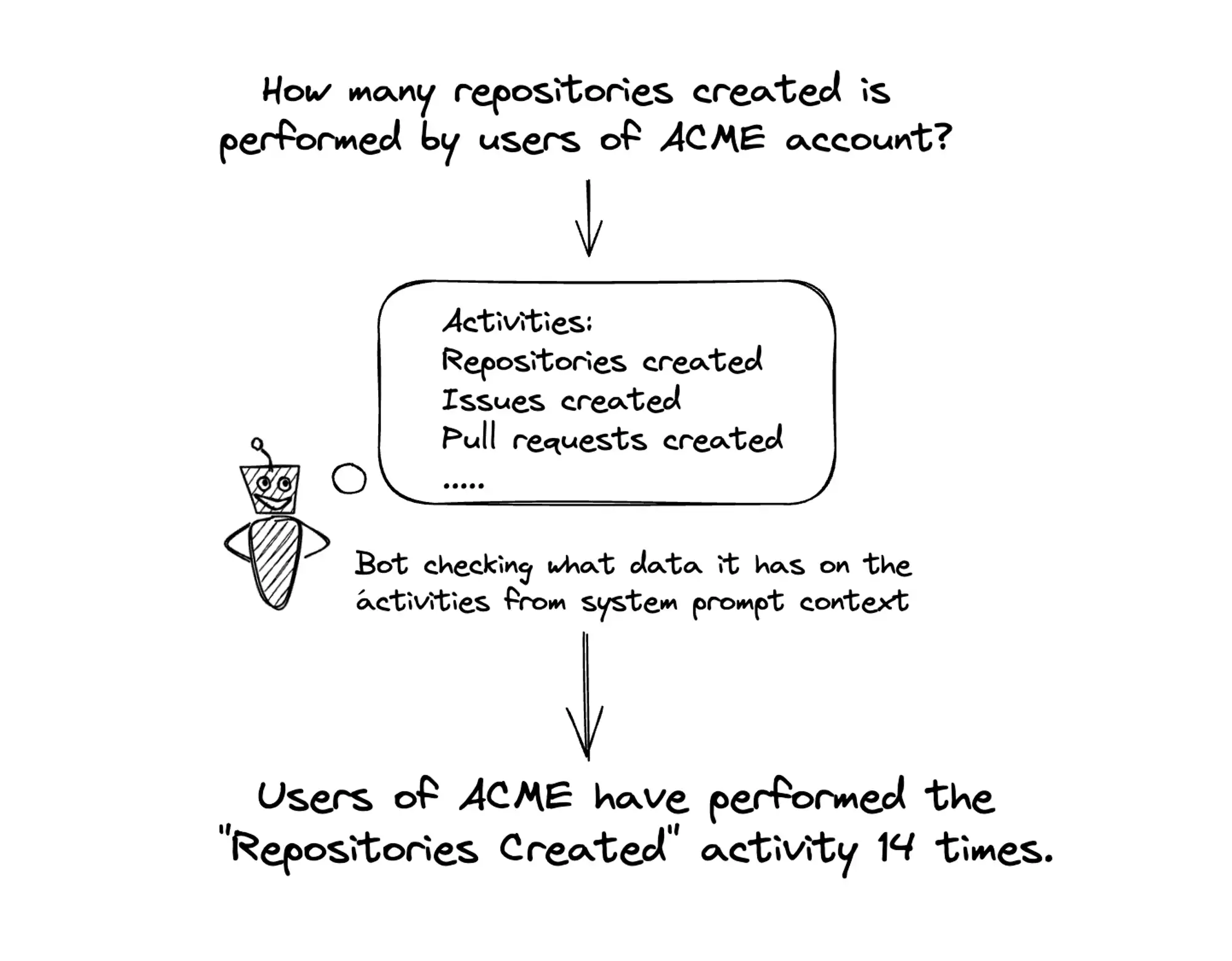
For example we pass details about what activities are there in the workspace and details for an activity if any. Since the data for activities can differ from workspace to workspace this is done dynamically to give context about the active workspace. If the bot does not know about the activities and is asked to get the details on “issues created by account A” then it does not know what “issues” is and instead of getting details for the activity with name “issues” it might try to get the details of an account and check if there is something related to “issue” or not. Moreover if a user writes “issue” instead of ‘issues' it might say that there is no activity with this name in the system. But after passing the context on activities the bot knows the available activities in the system and can correctly get the data on that activity instead of calling the function to get account details hence improving the overall accuracy of the bot
Few-shot function prompts
Following the last example the bot has context on some of the data available in the platform but it is still not enough to make sure that it knows all the parameters of our system and how to get that data in the best way
To improve the accuracy we started using function prompts to give LLM context on what function can be called for a specific question since some of the parameters in the function response can overlap. Example - bot can call 10 functions to get account details while the same can be done by another function which reduces the details but provides an overview for all 10 accounts.
Here is an example of few-shot function prompt in javascript
const payload = {
model: "gpt-4o",
tools: [
{
type: "function",
function: {
name: "GetAccountDetails",
parameters: {
type: "object",
properties: {
id: { type: "string", description: "Account ID" },
},
},
description: "Get details of an account given id",
},
},
],
messages: [
{
role: "user",
content: "Tell me about account with ID 123",
},
{
role: "function",
name: "GetAccountDetails",
content: '{"id": "123"}}',
},
{
role: "user",
content: "Tell me about account, id: 456",
},
],
};const rs = fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
body: JSON.stringify(payload),
headers: {
"content-Type": "application/json",
Authorization: `Bearer ${OPENAI_API_KEY}`,
},
})
.then((res) => res.json())
.then((res) => console.log(res));Using a few-shot function prompts worked for us or at least so we thought as the functions were called in the manner that we wanted most of the time!
Later we found that around 5% of time the bot referred to the previous prompts with function as the actual function call and expected a assistant role based answer but since it is not provided in the prompts it hallucinated and answered with data that is not there.
One solution that might seem correct is to prompt the LLM to call the function for every question but some of the questions like What activities are there? can still be answered from the system prompt context so forcing the LLM to call a function was not the correct approach.
Chain of thought (COT) prompts
Based on the challenges faced after the few-shot examples, we took a look at how to do the COT prompts where we asked the bot to think before doing anything and adding a html token like <thought>{prompt goes here}</thought>.
This approach lets us pass function details like name and arguments that should be called similar to the few-shot but in a way that is much better as now after the user role the next prompt is with role assistant which the LLM uses to get an example of what should be done next instead of directly giving an answer and hallucinating.
Here is an example of the messages/prompts passed to the LLM with the thought token
[
{
role: "user",
content: "Tell me about account with ID 123",
},
{
role: "assistant",
content:
"<thought>I should call the function with ID 123, using arguments { 'id': '123' }</thought>",
},
];While testing this out I saw that the bot can still refer the prompts as the actual response and while asking a question like "Tell me about account with ID 456” it responds with "<thought>I should call the function with ID 456, using arguments { 'id': ‘456’ }</thought>" as the answer and does not call the function to get the details.
Since now we have a token we can easily catch this in the code by checking if response content has the token or not and if it does we make another call to the LLM to call the function with a user role message like “{role: ‘user’, content: ‘call the function’}” which in turns do call the function given we already provide the history context for previous questions and responses.
While testing this out we saw that the LLM can around 3% of the time give the result same as what is there in the example prompts which is again an issue but this time we can check the token that we have in the prompts and handle the same in the code by appending a `user` role prompt asking the LLM to call the previous function this ensures that the function is called instead of providing the prompt as response to the user.
Debugging & Logging
While implementing the chatbot one main question was How do we know if the error is from LLM or the functions passed to it? How do we replicate an issue faced by the user? These questions are critical to improve the overall visibility which then helps to easily work on improving the solutions as the issues are clear enough
In this example we will talk about how we at FunnelStory log and debug the issues faced by customers to ensure that we can replicate the same and improve the bot at the same time.
Logging LLM payload - We maintain the logs of what function the bot called for a specific question and what questions were added to the history along with the user’s question. This helps us to debug the issue locally and recreate it providing the same messages and test it out instead of asking the same question to the chatbot and hoping that the LLM makes the same mistake which is hard to do.
Handling the errors - There can be LLM api errors like hit token limit, errors in the function passed to the LLM ideally these are handled like any other system errors but in this case since we have a chatbot the UX is different from rest of the application so we handle and log the error internally while showing a fallback message to the user to ask the question again. This ensures that the UX of the chatbot is not broken and users are getting a response from the chatbot even if there is an error.
Updating the prompts - As more functionalities are added to the bot we ensure that the prompts are updated as well to ensure that the bot knows how to call the function in an expected manner.
Conclusion
In this blog post, we address LLM hallucinations faced in FunnelStory while implementing Felix, FunnelStory’s data-access chatbot. Starting with the issues that we faced, the blog dives into what steps were taken to improve the chabot’s accuracy and hallucinations: providing context in system prompts, optimizing function calling using few-shot examples, and guiding the decision making using thought prompts. Later in the blog we also discussed why it is important to have proper debugging and logging in place, and improving user experience with proper error handling.
While this is a significant improvement to the chatbot accuracy and hallucination, this is not the final solution and we are exploring the options below to improve it further.
https://platform.openai.com/docs/guides/optimizing-llm-accuracy
Next steps that can be taken:
Tree of thought https://www.promptingguide.ai/techniques/tot
Fine tuning the LLM - https://platform.openai.com/docs/guides/fine-tuning/when-to-use-fine-tuning