In this article
Why Churn Feels Like Magic (And How AI Reveals the Math)
Explore how AI churn prediction works with imperfect data, surfacing hidden signals months ahead to reduce attrition.

By Preetam Jinka
Co-founder and Chief Architect
Sep 30, 2025
5 min read
Last Updated: Oct 27, 2025
When Churn Feels Like Magic — Because You Don’t See the Math
Churn is a silent drain. It doesn’t necessarily announce itself. You see drops in usage, shriveling renewal rates, and reactive firefighting across your customer success org. But too few teams truly see the internal mechanics of churn — the hidden forces and gaps that lead to attrition.
This blindness creates a paradox: many believe that AI or predictive models require immaculate, perfect data. “If only we had better instrumentation, better logging, cleaner schemas…” is a refrain I hear often. But that’s a false barrier.
The reality is: you already have valuable signals. Even fragmented, scattered, or “messy” data can be woven into a mathematical model that surfaces what you don’t yet see.
The problem isn’t the data — it’s your mental model of what “AI and churn” means.
What People Get Wrong (and Why)
Here are a few common objections or mental blocks I hear:
“Our data is too noisy / incomplete / inconsistent.”
“We don’t have enough events or historical span for modeling.”
“We’d need to instrument more deeply before using any AI tool.”
“AI can’t explain its predictions — how would we trust it?”
These objections all stem from a misunderstanding: AI models (especially modern ones) can be robust to missingness, noise, or irregularity — and they can be built to tell you where your gaps are, not just predict outcomes.
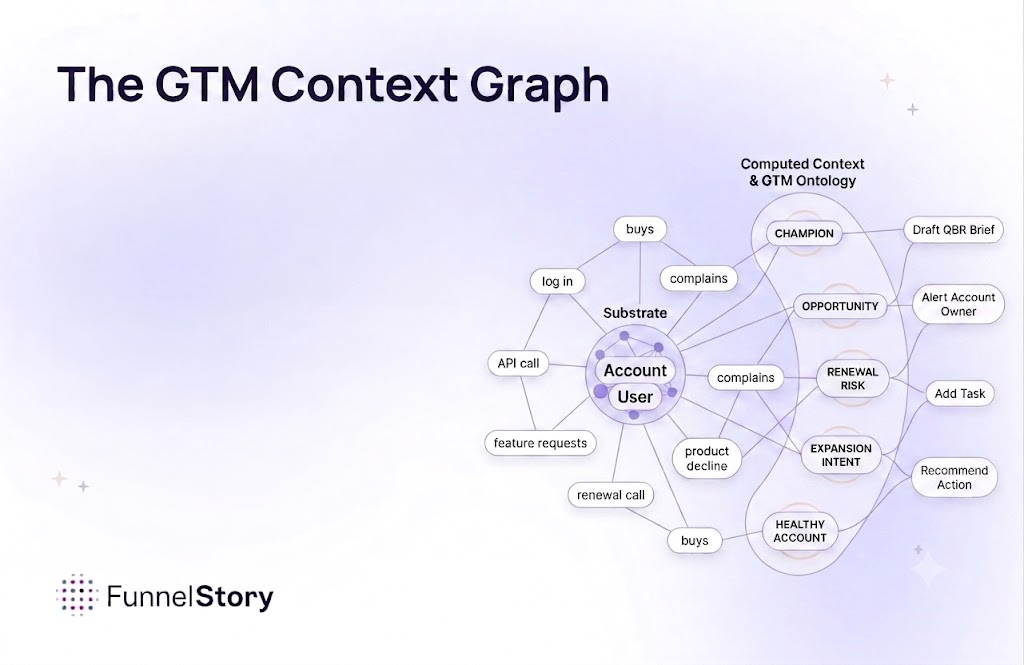
When you hear things like “Cut Surprise Churn by > 90%” in FunnelStory’s marketing, or claims of surfacing signals up to 3–9 months ahead, those come from applying reasoning layers, graph models, embeddings, and feature gaps remediation over the data you already have.
A recent FunnelStory post frames the issue well:
“Most companies track usage data and revenue trends to predict customer churn. But here’s the catch — the real …”
“With the right measurement, analysis, and action, you can turn [churn] into a growth opportunity.”
These statements hint at how the magic works: by combining multiple weak signals, surfacing gaps, and applying reasoning — not expecting perfect coverage from the start.
How AI Can Work with Imperfect Data
Here’s a rough sketch of how a model like FunnelStory might approach churn prediction in a “real-world” scenario:
1. Data Ingestion & Harmonization
Pull in diverse sources: product usage logs, CRM data, support tickets, emails, meeting transcripts, account notes. Normalize and unify across schemas. Use schema matching, embeddings, and knowledge graph techniques to relate disparate data points.
2. Feature Construction & Imputation
From those raw sources, extract candidate features: usage trends, feature adoption, sentiment in emails/chat, milestone misses, contract health, etc. For missing data, use imputation methods, proxy features, or inference to “fill the blanks.” The model doesn’t need every field — it needs enough signal and to know which missingness matters.
3. Model Training & Validation
Train supervised or hybrid models using historical data with churn labels. Use cross-validation, holdouts, and techniques like ensemble or regularization to mitigate overfitting. Crucially, the model can also surface where its predictions are weak — i.e. “this customer is flagged with low confidence because we don’t see their usage logs for 30% of the period.” That feedback helps your team decide where to instrument or chase data.
4. Gap Detection & Explainability
A good churn tool doesn’t just output “this account is risky” — it also highlights why, and what’s missing. Perhaps it sees that for this account, there’s no usage data for their primary module, or that there were no recent support tickets, or that sentiment turned negative in recent conversations. That clue tells you where your data is weak.
5. Actionable Signals & Timing
The goal is to catch churn before it becomes a cancellation. By combining multiple molecules of signal — e.g. declining usage + increasing negative sentiment + slack in milestone progress — the model can raise alerts 3–9 months ahead.
Over time, as you act on signals, feed results back in (did the customer recover or cancel?), you continuously retrain and refine.
Why Many Teams Don’t Believe It — And How to Bridge the Gap
They equate “AI” with “black box” or “requires perfect data.” Instead, reframe AI as “augmented reasoning” or “data synthesis + modeling.” The promise is not perfect certainty, but better visibility than human intuition alone.
They demand 100% coverage before trying. That’s backward. Try modeling with what you do have, see where it fails, then iteratively improve your instrumentation or data capture guided by model feedback.
They distrust predictions without explainability. Choose or demand models that include explainable outputs (feature importance, confidence intervals, “why this account”) and gap signals (where data is missing or weak).
They see churn tools as a “nice to have,” not core. But churn is revenue leakage. Even modest improvements in detecting churn early yield ROI. And the byproduct is better instrumentation, better data hygiene, and more aligned thinking across product, support, and CS.
A Realistic Roadmap for Teams
Start small, with what you have. Use a pilot — maybe 100–500 accounts — and build a basic predictive model using the strongest available features.
Inspect model failure modes. When the model mispredicts, dig in: is it because data was missing? Because certain classes of users aren’t represented? Use that insight to guide better logging, tracking, or structural changes.
Layer in unstructured data. Conversations, support tickets, meeting notes often reveal early signs of dissatisfaction. Models that ignore them leave huge blind spots.
Iterate toward hybrid reasoning. Combine rule-based heuristics (e.g. contract expiry, known accounts in risk) with ML models. Over time, let the model take more weight.
Close the loop. Take predicted risky accounts, run retention plays, measure which ones get saved — feed that back into the model.
Communicate insights, not just scores. To get buy-in, show your stakeholders why an account is flagged and what can be done.
Final Thoughts
The core misunderstanding many teams have is this: they’re waiting for perfect data before trusting AI, when in fact AI can help illuminate the gaps in your data. Tools like FunnelStory are built to reason over imperfect, real‑world systems — and surface the missing signals, the leading indicators, the heatmap of churn.