In this article
Building a GTM Context Graph: Notes from Production
Notes from three years building a GTM context graph in production. The 95% ontology finding, why pre-computed truth beats RAG, and where agent traces actually fit.

By Preetam Jinka
Co-founder and Chief Architect
Jun 16, 2026
15 min read
Last Updated: Jun 19, 2026
TL;DR
We've been building a GTM context graph at FunnelStory since 2023, focused on B2B revenue teams.
Five problems showed up in sequence: fusing structured and unstructured data, designing the ontology, pre-computing truths for reliability, permissioning, and token economics.
The biggest empirical finding: GTM ontology is roughly 95% stable across customers. That single finding drives most of our architecture.
The canonical model is bounded — source-system variation lives in queries and mappings, scoped within a defined typed schema, not in the ontology itself.
A context graph is not RAG. RAG retrieves context for a model at runtime; a context graph maintains durable state before the question is asked.
Agent traces matter — but as a refinement layer, not the foundation. You can't bootstrap from traces that don't exist yet.
We've been building a GTM context graph at FunnelStory since 2023. This is the engineering version of what we learned: five problems we had to solve, in the order they showed up, and why we made the bets we made.
There's an active public debate right now about what context graphs should be. Foundation Capital has framed the category as a trillion-dollar opportunity, with particular emphasis on decision-trace graphs. Animesh Koratana has argued for coordinate systems and ontology emerging from agent trajectories. Kirk Marple at Graphlit has pushed back on the prescribed-vs-learned dichotomy and argued for adopting foundational standards first. Daniel Davis has connected the conversation to the semantic web's heritage. These are smart, specific arguments worth engaging with — and the debate matters because the architecture that wins the next 24 months is the substrate that AI-native enterprise software will run on.
This note is my engineering perspective alongside theirs. After three years of building this layer in production at enterprise scale, I think there's a gap between the public framing and what production actually demands. The architecture decisions below were forced by failures we hit in front of real customers, in a specific order. The order matters, because it explains why our architecture ended up looking the way it does — and where I agree and disagree with the current public framings.
1. Fusing structured and unstructured data
A GTM organization's data lives in two fundamentally different shapes.
On one side: nominally structured records — CRM, billing, product usage events, ticket metadata. These turn out to be neither as clean nor as queryable as the shape suggests. Production-scale product usage in particular runs at volumes that defeat naive querying approaches, and we had to develop our own strategies for high-throughput event streams.
On the other side: unstructured content — sales calls, support conversations, internal Slack, emails, meeting transcripts. Semantic and latent, resistant to deterministic retrieval.
The market reflex in 2023 was "throw it all into a vector store and let the LLM figure it out." It doesn't work — not because vector retrieval is bad, but because it's the right tool for the wrong problem. Vectors are good at search: finding documents that semantically match a phrase. They're not the right tool for analytical questions like what is the current health of this account, which accounts look like the ones we lost last quarter, which renewal motions are at risk and why. Those questions require structured retrieval over computed facts. And structured data pushed through embeddings is worse than structured data queried directly — you trade precision for similarity and get neither.
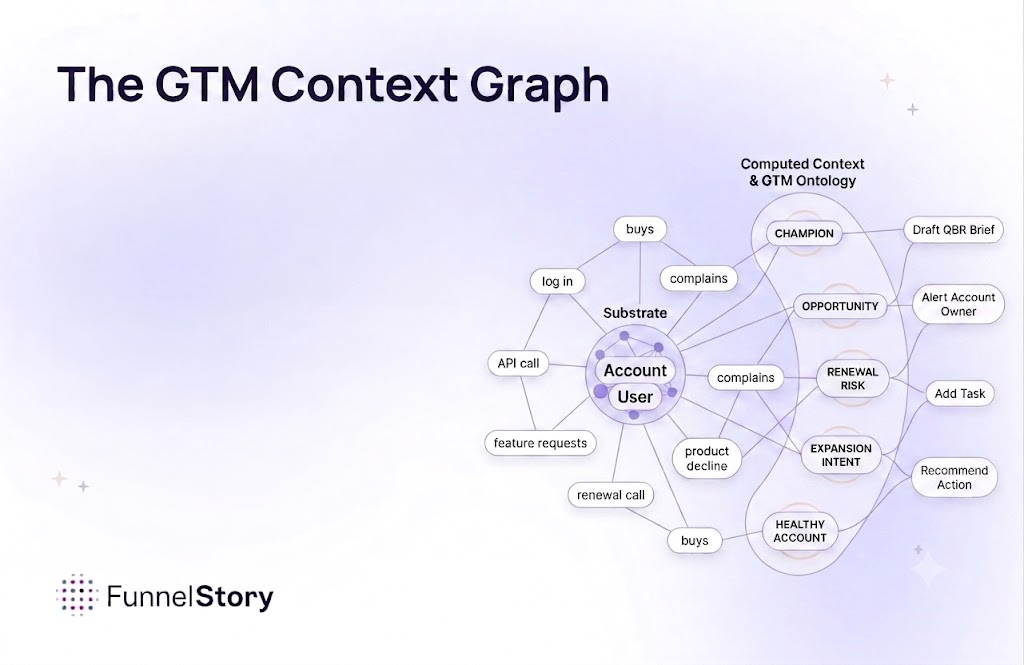
Our first architectural commitment: structured and unstructured data live in a single fused model, with each represented in the form it's best at. Structured records as records. Unstructured signal extracted into typed assertions tied to the same entities the structured data references. The fusion happens at ingest, not at query time.
That choice ended up determining almost everything else.
2. Prescribing the ontology — and the 95% finding
Once you commit to fusing structured and unstructured data, you have to answer a harder question: fused around what?
If the answer is "Schema.org Person and Organization," the model is too generic. A horizontal entity model doesn't know what a renewal motion is, what a champion is, what an expansion signal looks like, how deal velocity changes through stages. We needed a vertical GTM ontology.
This is where I partially diverge from Kirk Marple's argument for adopting foundational standards first. I agree with the spirit — don't NIH what already works, and Schema.org / CDM / the semantic web heritage are real prior art. But the available horizontal standards are too generic for GTM specifically. The vertical structure is what actually travels across customers; the horizontal standard is what gets adapted away to nothing once you reach the surface that matters.
This is where we made the bet that has become more contrarian over time. We prescribed the ontology — we built a defined model of GTM entities, relationships, and computed-state primitives up front. There's a parallel intellectual track in the industry arguing that the right approach is learned ontology: let the schema emerge from agent trajectories and decision traces over time. We took a different path.
What we found, deployment after deployment, is stronger than "vertical works better than horizontal." It was the finding that surprised us most:
GTM ontology is roughly 95% stable across customers.
The same core entities. The same core relationships. The same core computed-state primitives. The same canonical motions. A B2B revenue team at one company looks remarkably like a B2B revenue team at another company at the ontology layer, regardless of industry, segment, or size. Accounts are accounts. Renewals are renewals. Champion strength signals look the same wherever you find them.
The remaining ~5% is the long tail of customer-specific quirks. Real, has to be resolved at deployment, but they're quirks, not foundational redesigns. One customer ran two separate Salesforce instances — one for CS, one for Sales — where account names didn't match. The work was identity reconciliation at ingest. Another had a third-party billing system that needed reconciliation against CRM-recorded ACVs. Another had a homegrown product analytics system whose event schema didn't match anything off the shelf. All 5% problems. All deployment work, not foundational architecture.
The stability is itself a finding. It says the GTM domain has real underlying structure that travels across organizations. It's the reason a new customer can inherit 95% of the value the moment they connect, with only the 5% requiring on-deployment work.
From ontology to canonical model
The ontology answers what entities and relationships exist. The canonical model answers how varying source data gets mapped into that stable structure. They're related but distinct — and once you've prescribed the ontology, the canonical model is the engineering work that makes it operational.
Our canonical model is implemented as a two-layer architecture:
Connections define where data lives — Salesforce, HubSpot, Postgres, Snowflake, BigQuery, Databricks, Zendesk, Gong, Slack, Mixpanel, S3, and the long tail of others. Auth, security, and refresh schedules live here.
Typed data models define what source data normalizes into — 17 typed models covering accounts, users, activities, conversations, support, meetings, subscriptions, usage, products, and operational primitives. Each model has a defined property surface derived from the 95% stable ontology.
The translation from source to canonical happens through queries (SQL, SOQL, HubSpot blocks) plus column-to-property mappings. This is where the 5% deployment work lives — concretely, not abstractly. A customer's Account.segment property might be populated from a Salesforce custom field Account_Tier__c (with text variants like "Ent," "Enterprise," "ENT" normalized via enum mapping), HubSpot's customer_segment property (different case and format), or a Snowflake column customers.tier (integers mapped to the canonical enum). Type normalization, enum harmonization, and entity resolution all happen at this layer.
Two flavors of canonicalization run in parallel:
Managed
— for integrations with stable schemas (Zendesk support tickets, Gong calls, Slack messages), the canonical mapping is auto-applied. No per-customer configuration required.
User-configured
— for warehouses, CRMs with custom objects, and homegrown systems, the customer (or our team) provides the query and mapping. This is where the 5% deployment work shows up.
The system also bootstraps mappings automatically. During onboarding, AI-suggested models read connection metadata — warehouse table schemas, CRM object structures — and propose mapping definitions that the customer reviews, validates, and activates. This compounds across deployments: the more sources the system has seen, the better it bootstraps each new mapping. The 5% deployment work trends toward zero over time, not the other direction.
What matters about this architecture is that the canonical model is bounded. Variation across customers lives entirely in queries and mappings, scoped within a defined typed schema. The ontology stays stable; the mapping layer flexes. That's the difference between "every customer is a snowflake requiring bespoke schema design" and "every customer's source data maps into the same 17 typed models through configurable queries."
The unusual cases I mentioned above — the customer with two separate Salesforce instances and mismatched account names, the third-party billing reconciliation against CRM-recorded ACVs, the homegrown product analytics schema — were all handled at this mapping layer. None required redesigning the canonical schema. The ontology absorbed them; the mapping layer adapted to them.
I'll come back to what this means for the learned vs. prescribed debate.
3. Pre-computing truths — and the reliability problem
By the time the ontology was holding up under load, we were watching a different kind of failure.
The same question, asked by different users through the same Copilot, was producing different answers. "What is the health of the account?" at 10 AM came back differently than at 4 PM. Probabilistic retrieval was compounding badly across multi-step workflows. Agents would derive "high churn risk" one minute and "stable" the next, depending on which slice of context retrieval happened to surface.
The cause was that the analytical work — health bands, churn risk, expansion likelihood, sentiment, decision-maker mapping — was being done at inference time, inside the LLM, every time the question was asked. The LLM was acting as a probabilistic analyst on top of raw data. Unreliable by construction.
The architectural answer was to move that work upstream. Compute the truths at ingestion. Materialize them as structured facts with evidence pointers back to the source records that justify them. The agent doesn't reason its way to "92% churn risk" inside each user's session — it looks up a precomputed value generated once, deterministically, with precision/recall/F1 validation. Same answer for every user, every time.
This is the core architectural commitment that separates a context graph from RAG. Stated cleanly:
RAG retrieves context for a model at runtime. A context graph maintains durable state before the question is asked.
Solving reliability also forced evidence into the architecture as a first-class property. Every computed truth needs to be explainable — which ticket, which meeting transcript, which CRM field, which conversation supports this state. Without evidence, computed truths are just another opaque box. With evidence, the graph is auditable, and humans and agents both have reason to trust it.
4. Security and permissioning
The fourth problem only became visible once the previous three were solved. With a fused, ontology-grounded, precomputed graph in place, end users — and AI agents acting on their behalf — suddenly had a clean way to ask about anything in the company's GTM data.
Which immediately surfaced the question: should they?
Source systems already have permissioning. Salesforce knows which reps see which accounts. Zendesk knows which support teams own which tickets. Snowflake has row-level security. Gong restricts call access by team. A context graph that ignored those entitlements would be a compliance disaster — SOC 2 failure waiting to happen, worse depending on whether GDPR, HIPAA, or industry-specific regulations apply.
The architectural answer was to build the permissioning layer on top of the context graph, as part of what we call the action layer. The graph itself remains a complete, fused, computed model of GTM truth. The permissioning layer enforces, at query and action time, each user's existing entitlements from the source systems. The CIO and CISO don't have to invent a new permission model for the agent layer; we enforce theirs.
The action layer is also where workflows, alerts, tasks, CRM updates, and draft messages live. Actions need permissioning more urgently than queries do, because actions write back to systems of record on behalf of a user.
5. Token economics — and the realization
The fifth problem is the one everyone is talking about right now. We did not build for it. We discovered it.
When Claude and ChatGPT rolled out to actual enterprise users, the bills started arriving. Federated MCP-direct — the obvious architecture for "let the LLM access all our systems" — was running roughly 32x more expensive than CLI deployments. One renewal-intelligence query pattern, on raw federated access, burned about 1.6M tokens per run. At 2,000 users running that workflow once a week, that's 3.2B tokens per week. A CS organization running agents on raw data could burn a full year's AI budget in a few months.
The mechanism is familiar to anyone who's thought about distributed databases: federated MCP forces what's effectively a client-side join inside the model's context window. The agent calls Salesforce, then Zendesk, then Slack, then the product DB, pulls rows back into the LLM context, then reasons across the noise to glue them together. Databases moved away from that pattern decades ago for exactly this reason — when the server can co-locate and index data, push the join there instead of shipping rows to a client.
A context graph is the server-side join. All sources are pre-ingested, the join and the ranking are baked in, the computed truths are already there, and the agent gets one clean payload per call. On the same renewal-intelligence workflow, our context graph ran ~9 queries against tables that already held the answer — ~35k tokens, ~32 seconds. That's the derivation of the ~45x cost reduction.
The realization was that everything we'd built for the previous four problems was the answer to token hyperinflation too. We hadn't been optimizing for tokens. We'd been optimizing for ontology, reliability, evidence, and permissioning. The token economics fell out of the architecture as a structural side effect.
Pre-computed truth turned out to be the most expensive thing to skip.
What a GTM context graph actually requires
A context graph is not a database, a vector index, a data warehouse, or a log of decisions. Those can all be components, but they are not the thing itself.
For GTM specifically, five properties are required:
1. A vertical GTM ontology. A specific point of view on what matters in GTM — accounts, contacts, opportunities, deals, renewals, meetings, tickets, product usage, risk, signals, stakeholders, competitors, segments, next actions. ~95% stable across customers; the 5% deployment work is identity quirks, schema variants, and edge cases. Not Schema.org. Not CDM. GTM-specific by design.
2. Entity resolution. The same customer, the same person, the same product issue, mapped consistently across CRM, support, product analytics, calls, Slack, email, billing, and documents. This is also where the 5% deployment quirks get reconciled.
3. Computed state. Health bands, churn risk, expansion likelihood, sentiment, key issues, deal movement, support escalation, champion strength, renewal blockers, segment classification — generated at ingest, validated with precision/recall/F1, refreshed on a cadence. The model stops doing analyst work and sticks to judgment and language on top of facts it can already trust.
4. Evidence. Every computed truth carries pointers back to the source material that justifies it — the ticket, the meeting transcript, the CRM field, the product event, the Slack thread. Without evidence, computed state is just another opaque box.
5. Actionability. A context graph isn't only for answering questions. It triggers workflows, creates tasks, updates systems of record, drafts messages, and guides agents. Gated by the permissioning model.
Concretely, what these properties produce in practice: a normal data system knows that an account has tickets, meetings, opportunities, and product usage events. A GTM context graph knows that the account has an unresolved product issue affecting renewal risk, that the economic buyer has gone quiet, that three support tickets point to the same device replacement pattern, and that the right action is to alert the account owner before the next QBR.
That's the difference between storing customer data and understanding customer state.
Where agent traces actually fit
I want to come back to the prescribed-vs-learned ontology question — engaging directly with the public framings — because I think the current debate gets the destination right but the sequencing wrong.
The argument for learned ontology, most fully articulated by Animesh Koratana, is that schema emerges from agent trajectories as a coordinate system the system discovers over time. It's intellectually compelling. As AI agents proliferate inside enterprises and accumulate execution histories, those traces will be real signal. They'll sharpen ontology in edge cases, surface organization-specific decision patterns, refine agent playbooks based on what actually produces outcomes, and capture the long tail of tacit organizational knowledge that no prescribed ontology fully models.
Foundation Capital's emphasis on decision-trace graphs gets the importance of decisions right — decisions are the unit of work that AI agents will increasingly own, and traces are how that work becomes legible. Where I diverge is on the architectural role of the trace. Foundation Capital's framing treats the trace as the structure. I think the trace is a refinement signal that sharpens and extends an existing structure. The two views are closer than they sound, but the sequencing matters.
I'm not anti-trace. I'm sequenced.
The problem with treating traces as foundational is that they require agents to already exist, running on top of something. You can't bootstrap a context graph from traces that haven't been generated yet. New customers have no traces. Greenfield deployments have no traces. The foundation has to exist first — the ontology, the entity resolution, the computed truths, the evidence. Then agents can run on top of it. Then traces compound the value of a foundation that's already producing reliable intelligence.
This is also where the 95% finding does most of its work. If GTM ontology were only 50% stable across customers, learned ontology would be the obvious bet — every deployment would be mostly bespoke, and the system would need to discover its own schema. Because GTM ontology is ~95% stable, the foundation is reusable from Day 1. Traces become a refinement signal layered on top, not a bootstrapping mechanism.
The position is foundation-first, traces-second. Animesh, Foundation Capital, and I are arguing about which way the arrow points, not whether traces matter. The arrow points from foundation to traces, not the other way around.
What's next
Today the graph makes GTM state queryable — account health, risk, expansion likelihood, key issues, evidence, and recommended actions. It already supports questions like "which accounts look most like the ones we lost last quarter." The next surface is richer counterfactual and intervention planning on top of the same model — an expansion of the architecture, not a separate bet.
The architecture decisions we made weren't theoretical. They were forced by failures we hit, in sequence, in front of real customers. Some of them look more contrarian today than they did in 2023. Most have held up under scrutiny. I'm publishing this because the category is forming now, the public framings are landing now, and the debate benefits from a voice that's been in production the whole time — alongside Foundation Capital's framing, Animesh Koratana's argument, Kirk Marple's standards position, and Daniel Davis's semantic-web heritage thread.
The debate continues. Happy to engage with anyone who wants to go deeper on any of it.